Overview
With the rapid advancement of artificial intelligence (AI) technologies such as foundation models, the demand for computational resources is growing at an explosive rate that far exceeds the evolution of supercomputers. Social implementation of computational resources that are low-cost, low-environmental impact will be essential to fill the gap.
Preferred Networks(PFN) has developed the MN-Core™ series of deep learning processors (accelerators) jointly with Kobe University to support the vast amount of computational power required for foundation models and other AI technologies. PFN is also building large-scale computer clusters (supercomputers) powered by the MN-Core series.
MN-Core Series
Compared with general-purpose chips, custom chips specialized for the training phase in AI can show significantly higher performance albeit limited functions.
The MN-Core series of proprietary processors co-developed by PFN and Kobe University features high peak performance and energy efficiency than conventional general-purpose processors thanks to its dedicated circuit for performing matrix operations, an essential process in deep learning, and fully deterministic architecture that allows precise software control of the hardware resources.
Unlike conventional processors, the MN-Core series have no program counters or command decoders in each of the accelerators'processing elements (PEs). All PEs operate synchronically while directly receiving instructions from the host CPU. This feature solves common problems in conventional accelerators such as the work imbalance due to each arithmetic unit operating non-synchronically and subsequent synchronization costs, as well as bottlenecks in instruction supply.
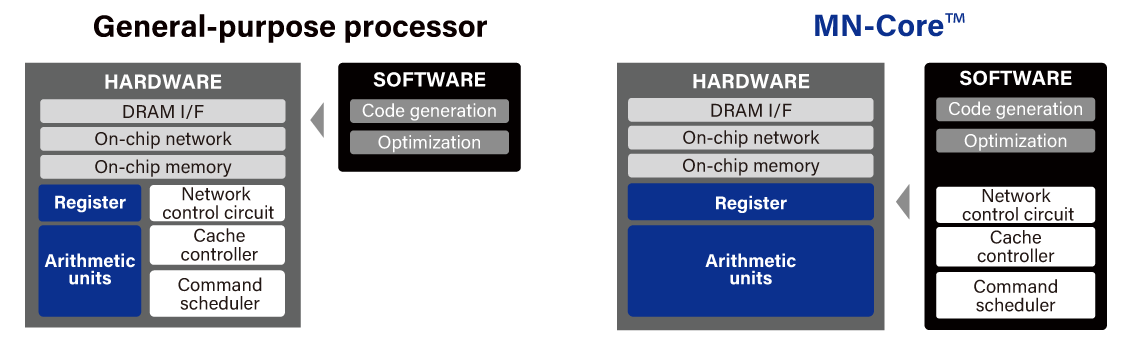
MN-Core has matrix arithmetic units (MAUs) densely mounted in its hardware architecture. Entirely composed of SIMD with no conditional branch, the simple architecture maximizes the proportion of arithmetic units on the silicon area. The MABs (matrix arithmetic blocks), each consisting of four PEs (processor elements) and one MAU (matrix arithmetic unit), have a hierarchical structure. This allows flexible programming as each hierarchical level can have multiple modes such as scatter, gather, broadcast and reduce.
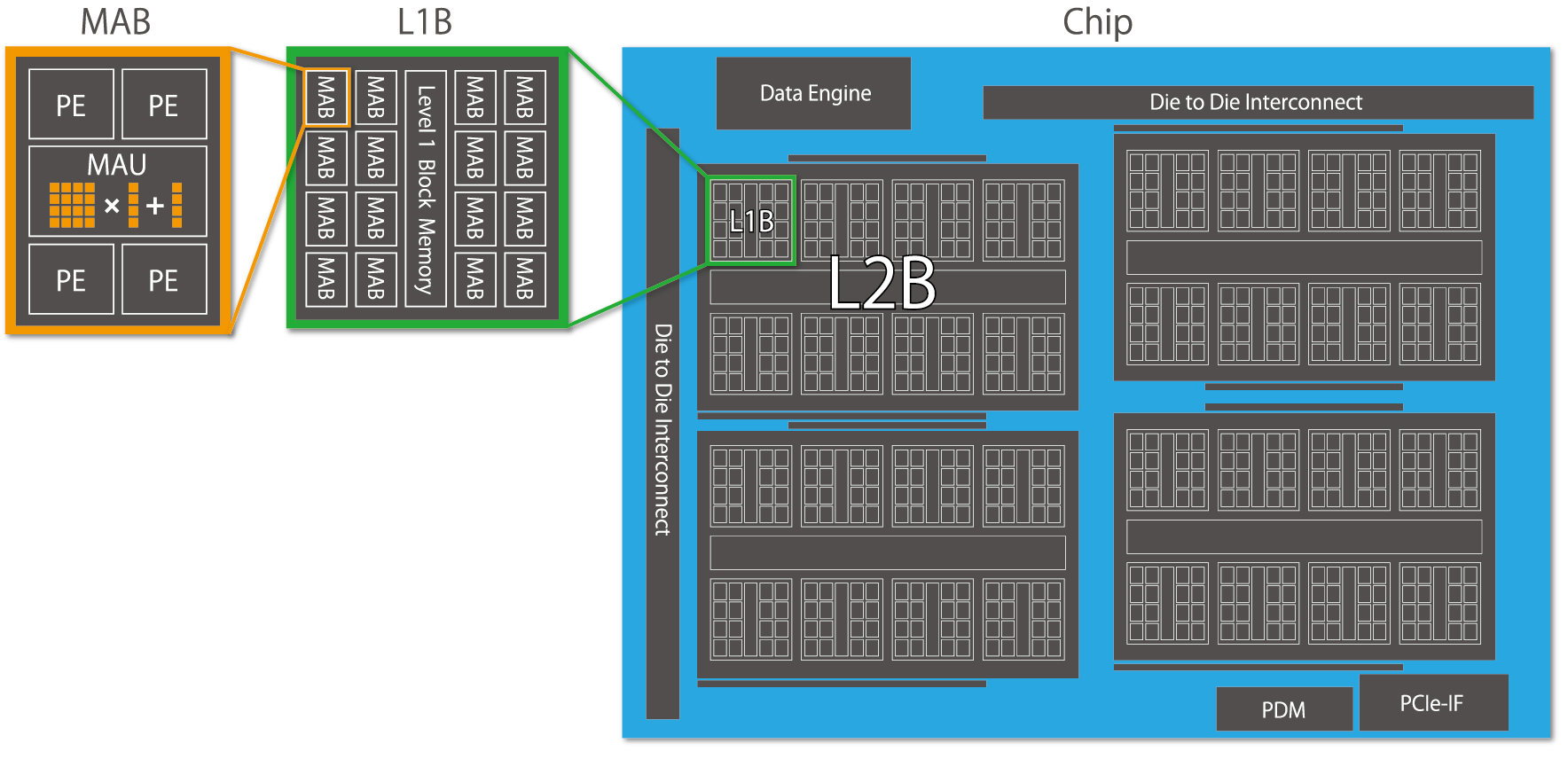
PFN also develops a compiler specifically for the MN-Core series so that users can harness its full potential without making major changes to existing AI workloads. The MN-Core compiler generates and supplies optimal instructions and moves data from computational graphs defined with high-level languages such as PyTorch and JAX. To efficiently perform different levels of processes from computational graph-level control to low-level instruction generation, the MN-Core compiler divides the problems according to their levels of abstraction and thus consists of components that make it easy to make improvements at the respective level.
MN-Core
The first-generation MN-Core consists of four dies integrated into one package. With each die has 512 MABs, the processor has a total of 2,048 MABs. Developed in the TSMC 12nm process, the first-generation MN-Core has higher peak performance and energy efficiency than other accelerators with the same process.

MN-Core (first generation) specifications
| Estimated power consumption (W) | 500 |
| Peak performance (TFLOPS) | 32.8 (DP) / 131 (SP) / 524 (HP) |
| Estimated performance per watt (TFLOPS / W) | 0.066 (DP) / 0.26 (SP) / 1.0 (HP) |
In 2020, PFN built MN-3, a supercomputer powered by 160 MN-Core processors connected with a specialized interconnect. MN-3 has topped the Green500 ranking of the world’s most energy-efficient supercomputer multiple times.
MN-3 Green500 Results
| June 2020 | November 2020 | June 2021 | Jovember 2021 | |
| Ranking | #1 | #2 | #1 | #1 |
| Energy efficiency | 21.11 GFlops/W | 26.04 GFlops/W | 29.70 GFlops/W | 39.38 GFlops/W |
| Execution efficiency | 41% | 53% | 58% | 64% |
MN-Core 2
MN-Core 2 is the second generation model in the series that boasts a top-class energy efficiency. Compared with the first-generation MN-Core, the second generation has larger memory bandwidth and smaller size, allowing high-density positions in compact blades.

MN-Server 2 was designed to accommodate eight MN-Core 2 accelerator cards. MN-Pod 2, which consists of six nodes of MN-Server 2, can perform half-precision floating point calculation at the speed of 18.9 PFlops.

MN-Core 2

MN-Server 2

MN-Pod 2
MN-Core 2 catalog specifications
| MN-Core 2 | MN-Core 2 (efficiency) | MN-Pod 2 | |
| FP64 | 12 TFlops | 37.24 GFlops/W | 590 TFlops |
| FP32 | 49 TFlops | 148.9 GFLops/W | 2,359 TFlops |
| TF32 | 98 TFlops | 297.9 GFlops/W | 4,719 TFlops |
| TF16 | 393 TFlops | 1,192 GFlops/W | 18,874 TFlops |
PFN plans to provide the MN-Core series’s highly efficient computing power to external parties in various forms.
Applications
The MN-Core series processors have shown significantly higher performance for actual AI workloads than GPUs thanks to its high energy efficiency and high peak performance.
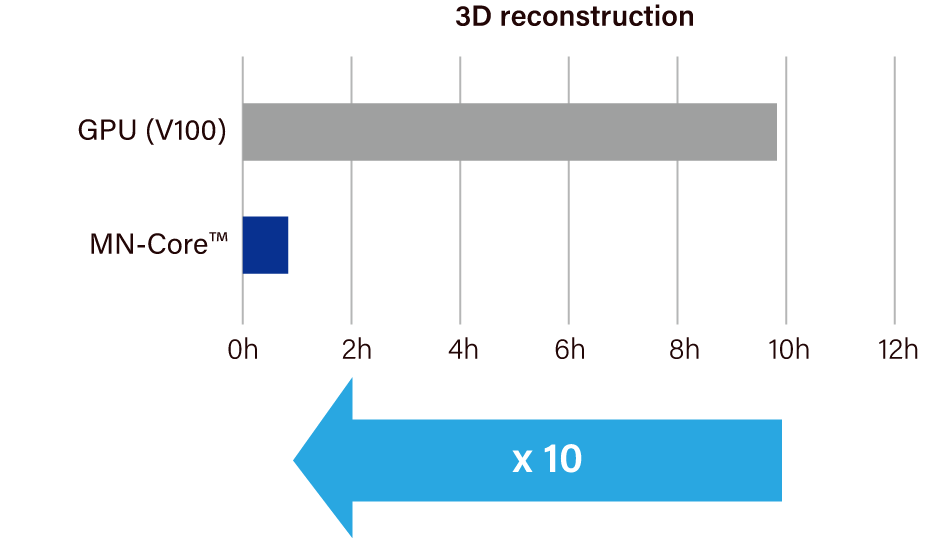
First-generation MN-Core achieved a tenfold increase in speed for neural network-based reconstruction of thousands of 3D models from 2D images for PFN 3D Scan.

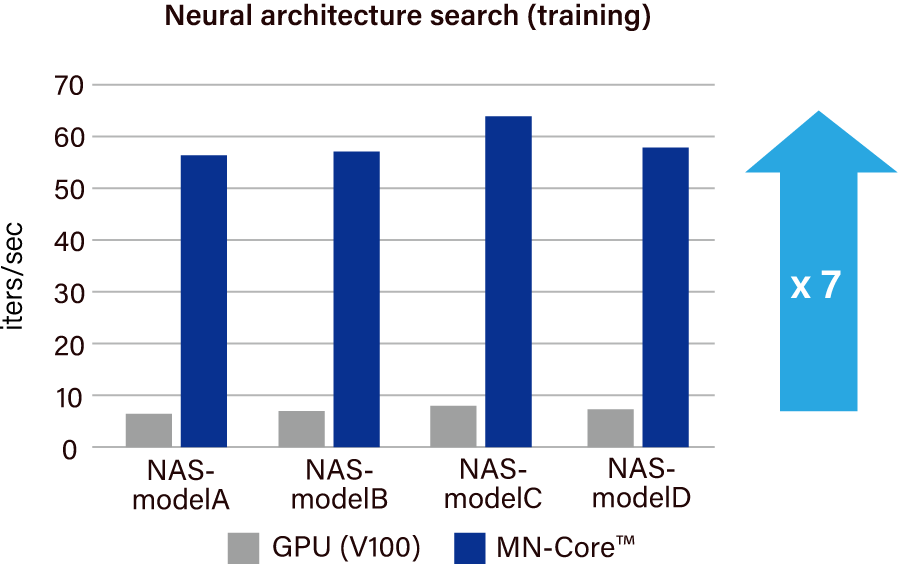
Automatic optimization of the image recognition model for kachaka, an autonomous mobile robot for home that are currently sold in Japan, was seven times faster when powered by MN-Core™ than GPU.

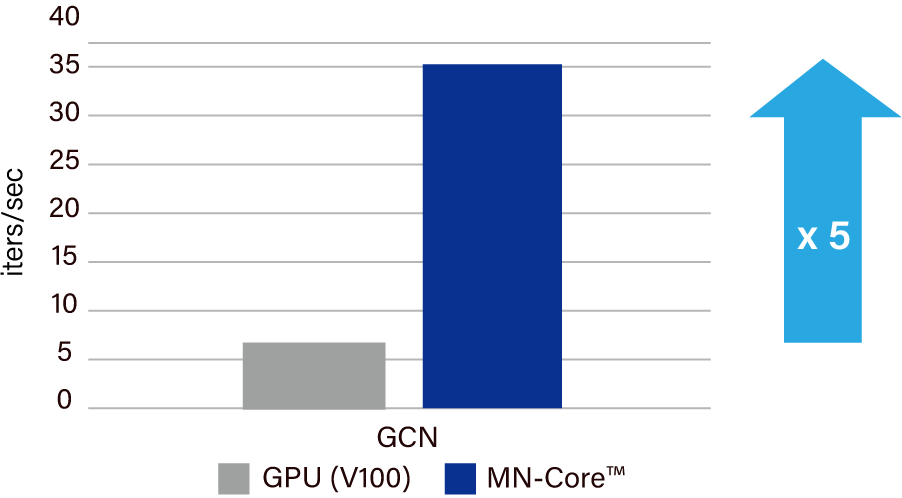
The speed for neural network-based atomistic simulation of new materials on Matlantis was over five times higher with MN-Core™ than GPU.
Resources
MN-Core 2 Software Developer Manual (MN-Core 2 SDM)
Contact
mncore-inquiry[at]preferred.jp
Our team

MN-Core team members

Kobe University professor Junichiro Makino (left) and Tokyo University professor emeritus Kei Hiraki (right) who are also PFN members (Photo provided by: Mari Inaba, an associate professor of The University of Tokyo)
MN-Core™ is a trademark or a registered trademark of Preferred Networks, Inc. in Japan and elsewhere.