Overview
AI/基盤モデルが必要とする計算資源はこれまでのスーパーコンピュータの進化の速度を大幅に上回り、爆発的に増加しています。技術の社会実装に向けて、低コスト/低環境負荷な計算資源が求められています。
Preferred Networks(PFN)は、AI/基盤モデルに要する高速かつ莫大な計算能力を賄うため、深層学習を高速化するプロセッサー(アクセラレータ)MN-Core™シリーズを神戸大学と共同開発し、MN-Core™シリーズを用いた大規模コンピュータクラスター(スーパーコンピュータ)の構築を進めています。
MN-Core Series
莫大な計算量を必要とする深層学習において、計算の高速化は大きな課題のひとつです。
AI/基盤モデルの学習フェーズに最適化した専用チップは、汎用用途のチップに比べ、機能を限定することで高い処理性能を発揮することができます。
PFNが神戸大学と共同で独自設計したMN-Coreは、AI/基盤モデルで必要となる行列演算の専用回路を搭載し、ソフトウェアによるハードウェア資源の細粒度な制御を実現するfully-deterministic Architectureを採用することで従来の汎用プロセッサに対して高いピーク性能と電力あたり性能を実現します。
MN-Core™シリーズプロセッサーは、従来のプロセッサーとは異なり、アクセラレータ上の各processing element (以下PE)がそれぞれのプログラムカウンタや命令デコーダを持ちません。すべてのPEは完全に同期的に動作し、ホストCPUで生成された命令列をホストから直接受け取って動作します。
これにより、今日のアクセラレータ上でしばしば発生する、アクセラレータ上の各演算単位が非同期に動作することによるワークインバランスとそれに伴う同期コストを削減し、ならびにインストラクションキャッシュなどの命令供給系によるボトルネックといった問題を解決します。
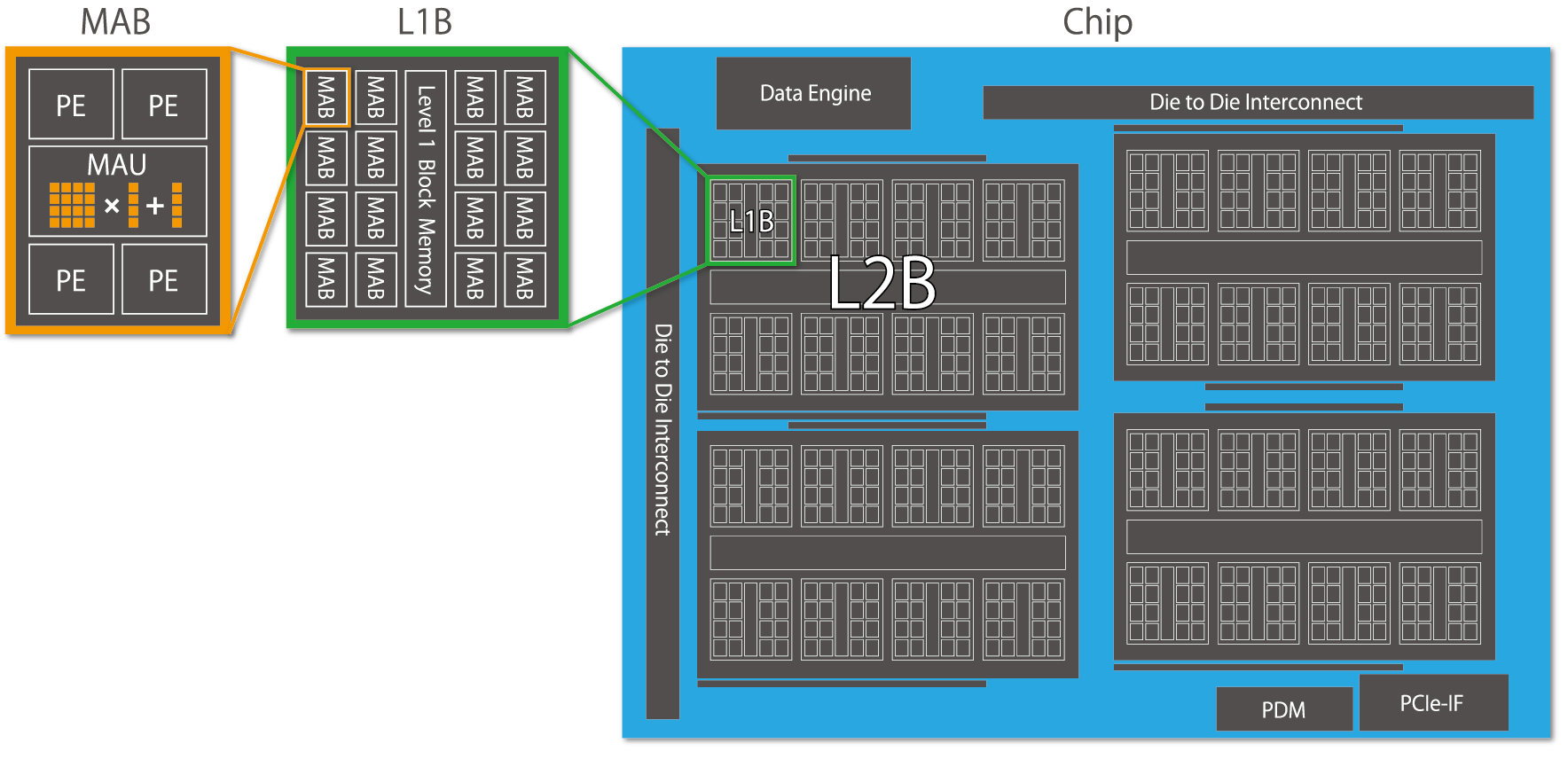
MN-Coreは極めて高密度にハードウェア実装された行列演算器(MAU、Matrix Arithmetic Unit)を持ちます。条件分岐のない完全SIMD動作をするシンプルなアーキテクチャを採用することによって、シリコンの面積に対して演算器の占める割合の最大化を実現します。MAUと4つのPEを合わせた行列演算器ブロック(MAB、Matrix Arithmetic Block)は階層的に配置され、階層間でスキャッター、ギャザー、放送、縮約といった複数のモードを持たせることで、柔軟なプログラミングを可能にしています。
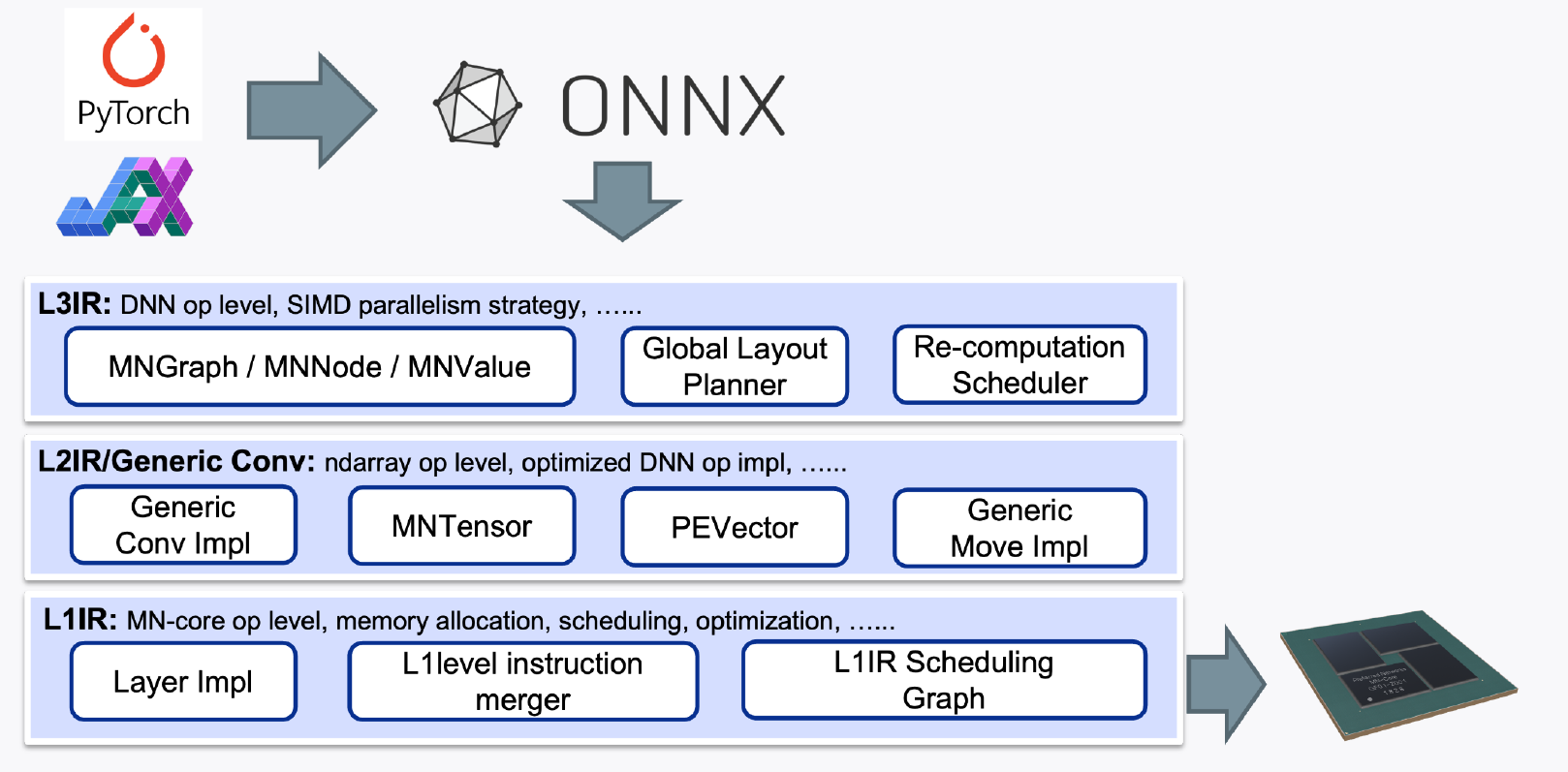
既存のAI Workloadに大きな改変を加えることなく、スリムかつパワフルに設計されたMN-Core™シリーズプロセッサーの性能を引き出すために、PFNではMN-Core™向けコンパイラを開発しています。 MN-Core™向けコンパイラはPyTorchやJAXなどの高位言語で定義された計算グラフから最適な命令生成、データ配置、命令供給などを行います。計算グラフレベルの操作から、低レベル命令生成までを最適かつ効率的に行うために、MN-Core™向けコンパイラは問題を抽象度に応じて分割し、コンポーネント単位でアルゴリズムの改善が可能な設計を行っています。
MN-Core
MN-Core™第1世代は4ダイ1パッケージで構成されており、ダイにつき512個、計2048個の行列演算ブロックが集積されています。TSMC 12nmプロセスで製造されたMN-Core™第1世代プロセッサーは、同一プロセスを採用する他のアクセラレータに対して非常に高いピーク性能及び、電力当たり性能を実現します。

MN-Core第一世代チップ仕様
| 消費電力 (W、予測値) | 500 |
| ピーク性能 (TFLOPS) | 32.8 (倍精度) / 131 (単精度) / 524 (半精度) |
| 電力性能 (TFLOPS / W、予測値) | 0.066 (倍精度) / 0.26 (単精度) / 1.0 (半精度) |
PFNではMN-Coreの第一世代プロセッサーを全体で160基使用し、それらを専用のインタコネクトを介して相互接続したスーパーコンピュータであるMN-3を2020年に構築し、運用しています。MN-3は世界のスーパコンピュータ電力効率ランキングであるGreen500の世界首位を複数回獲得しその極めて高い省電力性能を実証しています。
MN-3 Green500実績
| 2020年6月 | 2020年11月 | 2021年6月 | 2021年11月 | |
| ランキング | 1位 | 2位 | 1位 | 1位 |
| 電力効率 | 21.11 GFlops/W | 26.04 GFlops/W | 29.70 GFlops/W | 39.38 GFlops/W |
| 実行効率 | 41% | 53% | 58% | 64% |
今後MN-Core™ seriesプロセッサーの効率的な演算能力を様々な提供形態で外部提供を行っていく予定です。
MN-Core 2
MN-Core第2世代となるMN-Core 2は、世界最高水準の電力性能(消費電力あたりの演算性能)を持つプロセッサーです。第一世代のMN-Core™と比較して高いメモリ帯域を実現し、かつ小型のブレード形状となり設置密度が大幅に向上しています。


MN-Core 2
MN-Core 2 カタログスペック
| MN-Core 2 | MN-Core 2(電力効率) | |
| FP64 | 12 TFlops | 37.24 GFlops/W |
| FP32 | 49 TFlops | 148.9 GFLops/W |
| TF32 | 98 TFlops | 297.9 GFlops/W |
| TF16 | 393 TFlops | 1,192 GFlops/W |
Products
MN-Core 2ボードを8枚搭載するラックマウント型5Uサーバ。
型番:MNS2V1
搭載AIアクセラレータ/数:MN-Core 2 / 8枚
AIアクセラレータ総理論演算性能:TF16 3.1PF
標準販売価格:2000万円(税抜)

MN-Core 2ボードを1枚搭載するデスクトップマシン。オフィス環境でも手軽に置くことが出来、MN-Core 2によるAIアクセラレーションを手軽に体感することが出来ます。
搭載AIアクセラレータ/数:MN-Core 2 / 1枚
AIアクセラレータ総理論演算性能:TF16 393TF

| 商品概要 | 型番 | 標準販売価格 | |
| MN-Core 2 Devkit | MN-Core 2 Devkit 本体のみ | MNC2DV1 | 200万円(税抜) |
| MN-Core 2 Devkit 基本セット |
MN-Core 2 DevKitに搬送、設置、初期セットアップ費用を込みとしたセット | MNC2DV1bk | 250万円(税抜) |
(注1):MN-Core 2 Devkit 基本セットの設置場所は日本国内に限ります。
Applications
高い省電力性と高いピーク性能を両立するMN-Core™シリーズプロセッサーを用いることで、様々な実際のAI WorkloadにおいてGPUを超える非常に高い性能向上を実証しています。
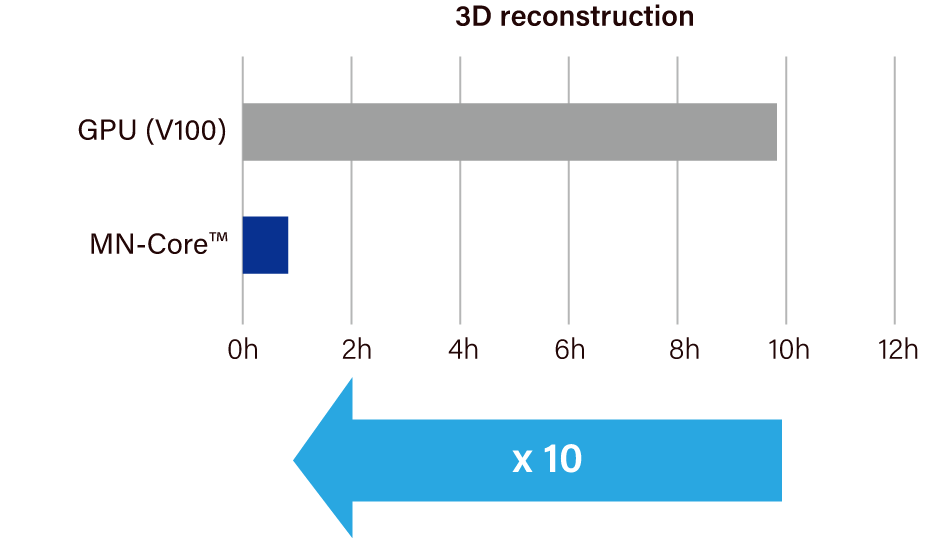
PFN 3D Scanにおけるモデルの再構成処理を10倍程度高速化、数千のオブジェクトのスキャンに活用

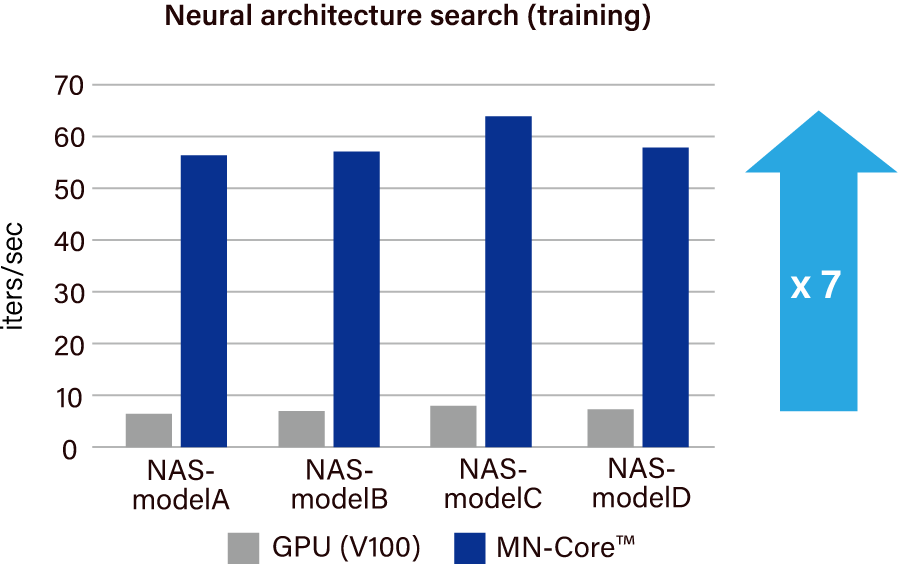
家庭用自律移動ロボット「カチャカ」向け画像認識モデル探索において、精度と処理速度を両立するモデル候補を従来比約7倍の速度で発見

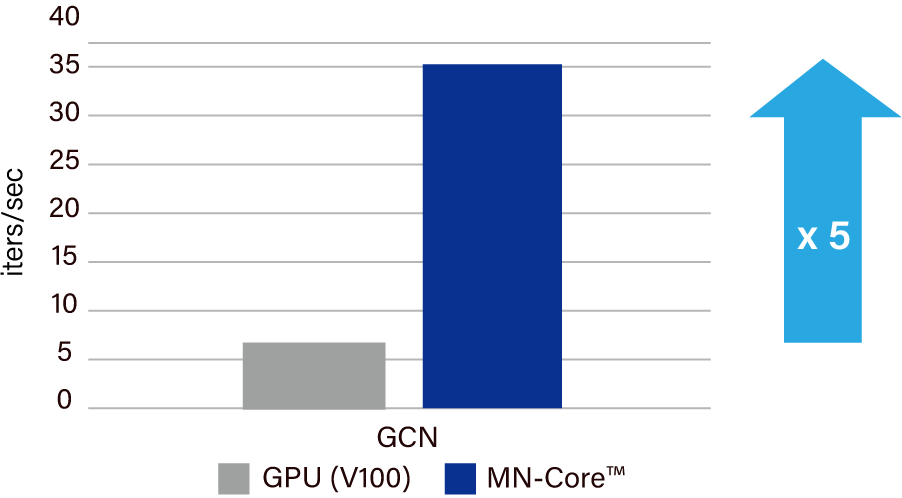
ニューラルネットワークを用いた原子レベルの新材料シミュレーション(Matlantis™上)を5倍以上高速化
Resources
MN-Core Software Development Manual (MN-Core 2 SDM)
MN-Core Emulator Environment (MN-Core emuenv)
Contact
mncore-inquiry[at]preferred.jp
Our team

MN-Coreチームメンバー

PFNメンバーでもある牧野淳一郎 神戸大学教授(左)と平木敬 東京大学名誉教授(右)
写真提供:稲葉真理 東京大学 准教授)
MN-Core™は、株式会社Preferred Networksの日本またはその他の国における商標または登録商標です。